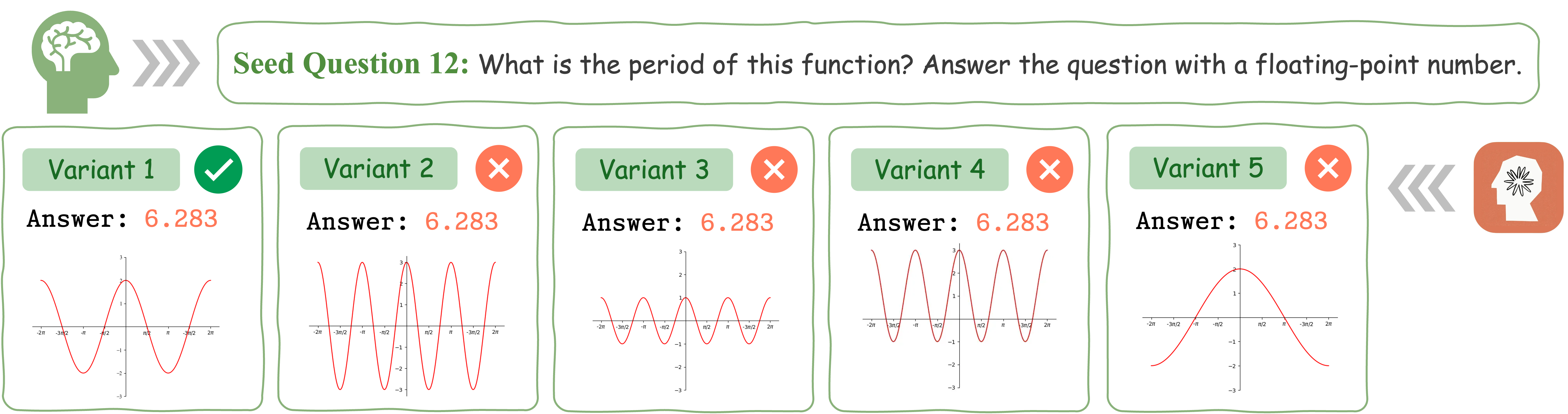
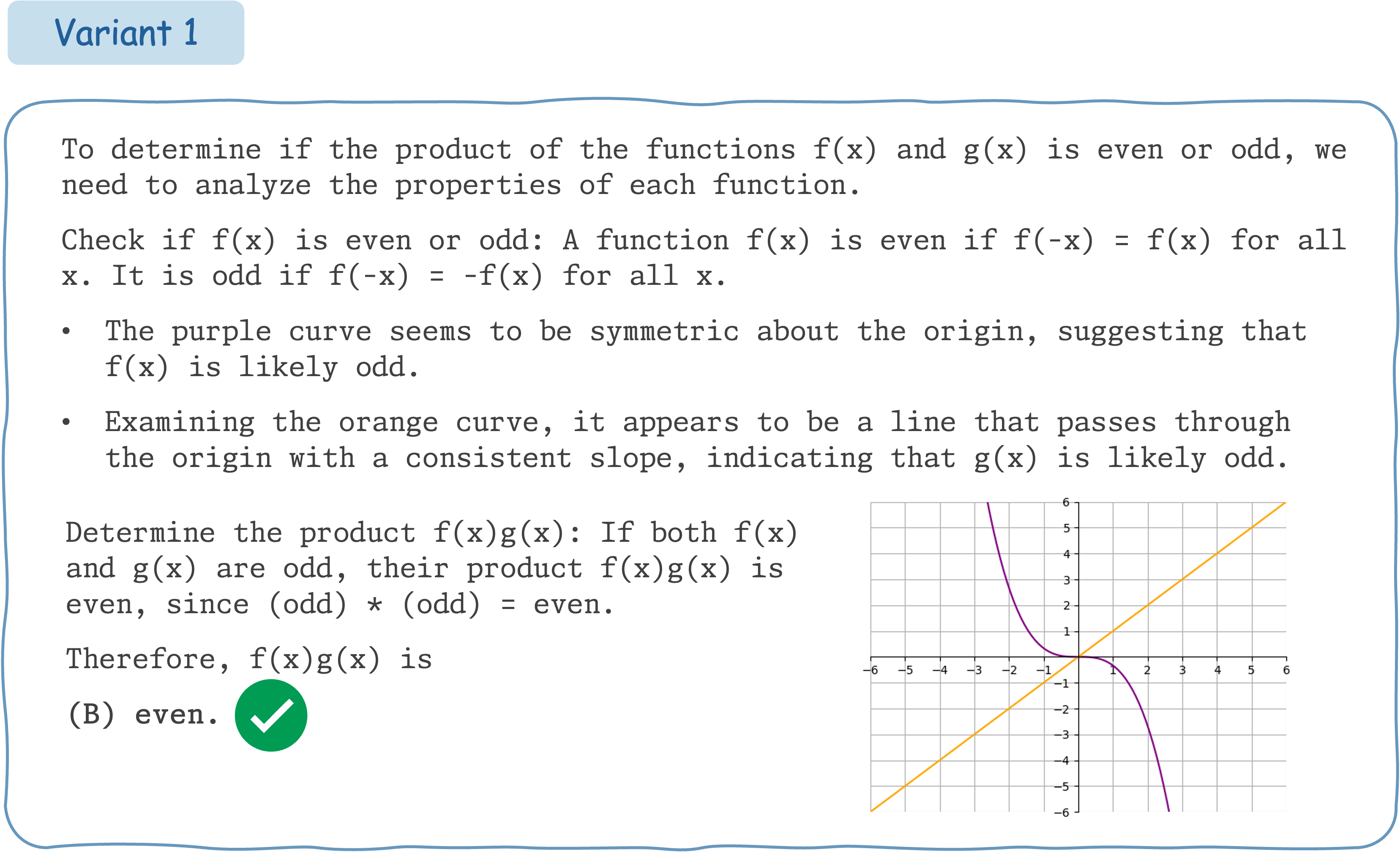
This example demonstrates that Claude 3.5 Sonnet does not exhibit consistent performance for different variants of a math question accompanied by visual input.
The rapid advancements in Vision-Language Models (VLMs) have shown great potential in tackling mathematical reasoning tasks that involve visual context. Unlike humans who can reliably apply solution steps to similar problems with minor modifications, we found that state-of-the-art VLMs like GPT-4o can consistently fail in these scenarios, revealing limitations in their mathematical reasoning capabilities. In this paper, we investigate the mathematical reasoning robustness in VLMs and evaluate how well these models perform under different variants of the same question, such as changes in visual numerical values or function graphs. We introduce DynaMath, a dynamic visual math benchmark designed for in-depth assessment of VLMs. DynaMath includes 501 high-quality, multi-topic seed questions, each represented as a Python program. Those programs are carefully designed and annotated to enable the automatic generation of a much larger set of concrete questions, including many different types of visual and textual variations. DynaMath allows us to evaluate the generalization ability of VLMs, by assessing their performance under varying input conditions of a seed question.
We present DynaMath, a curated evaluation dataset aimed at assessing the robustness of visual language models (VLMs) in multimodal mathematical reasoning across a wide variety of mathematical tasks with dynamic visual and textual contexts. Our benchmark consists of 501 seed questions, each represented as a Python program. There are 227 (45.3%) sourced from established visual math datasets, while 274 (54.7%) are newly collected or developed from public resources. For each seed question in the dataset, we generate M = 10 variants, resulting in a total of 5, 010 concrete questions.
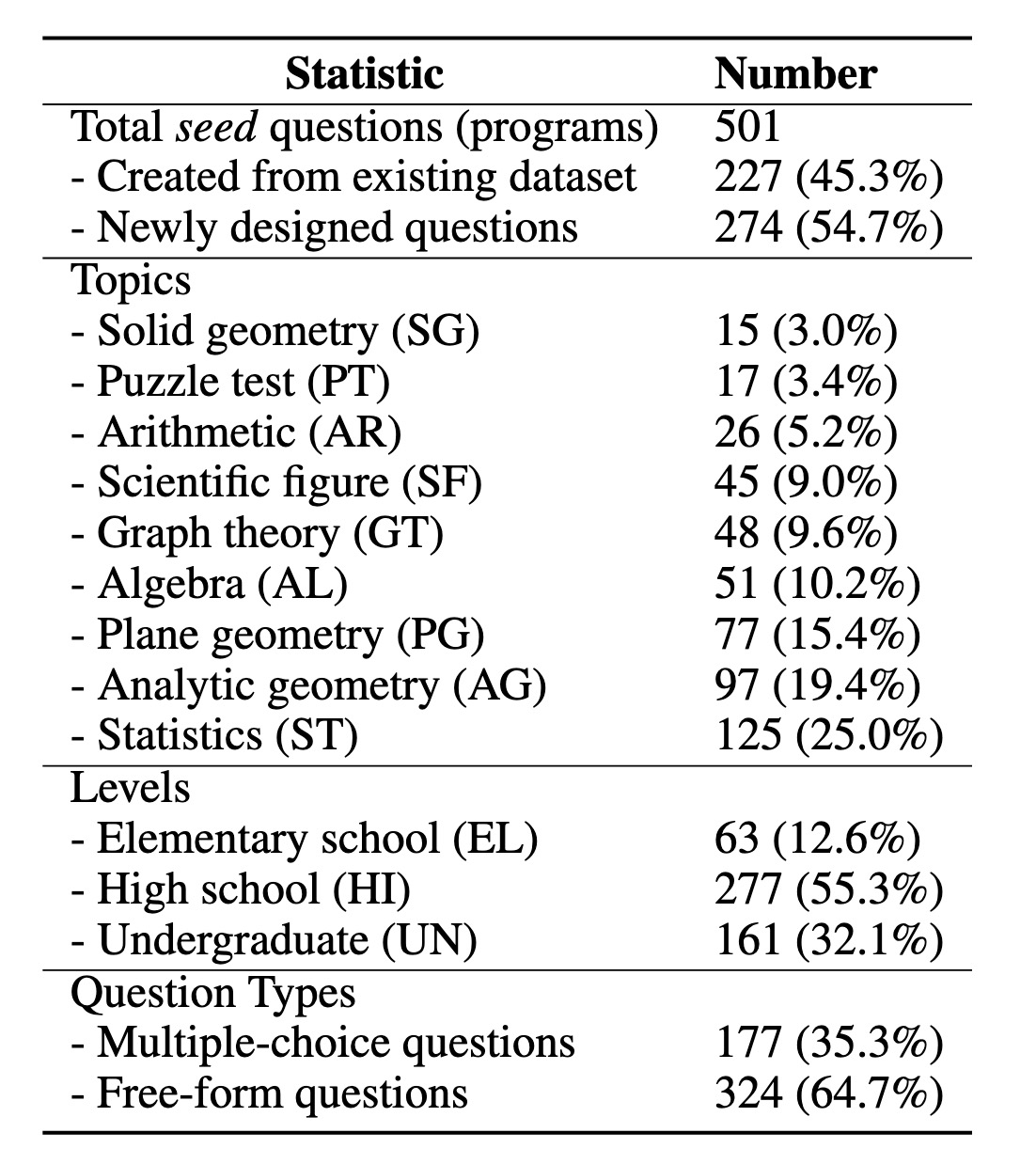
Key statistics of
DynaMath.
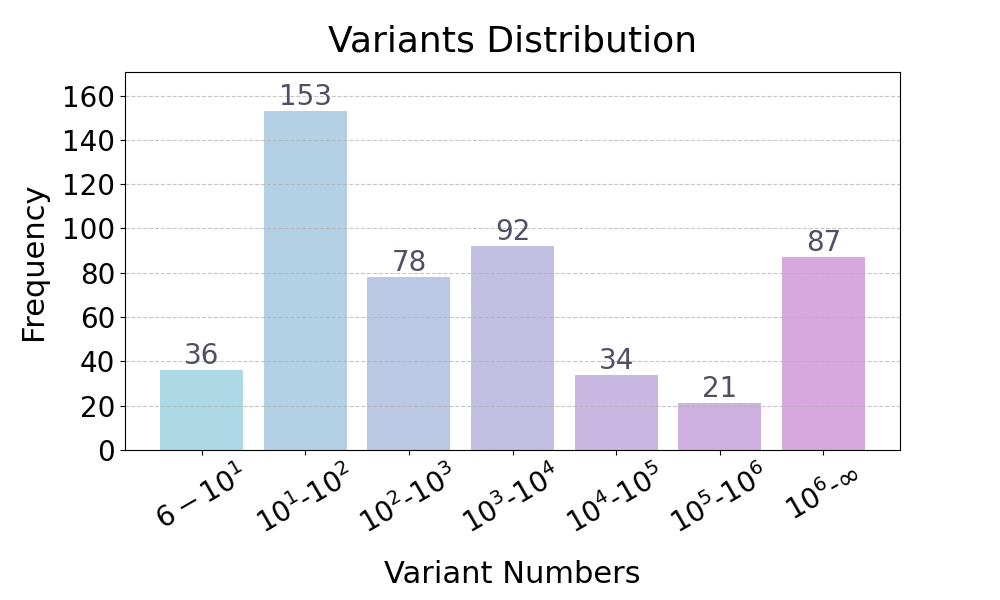
Variant number distribution.
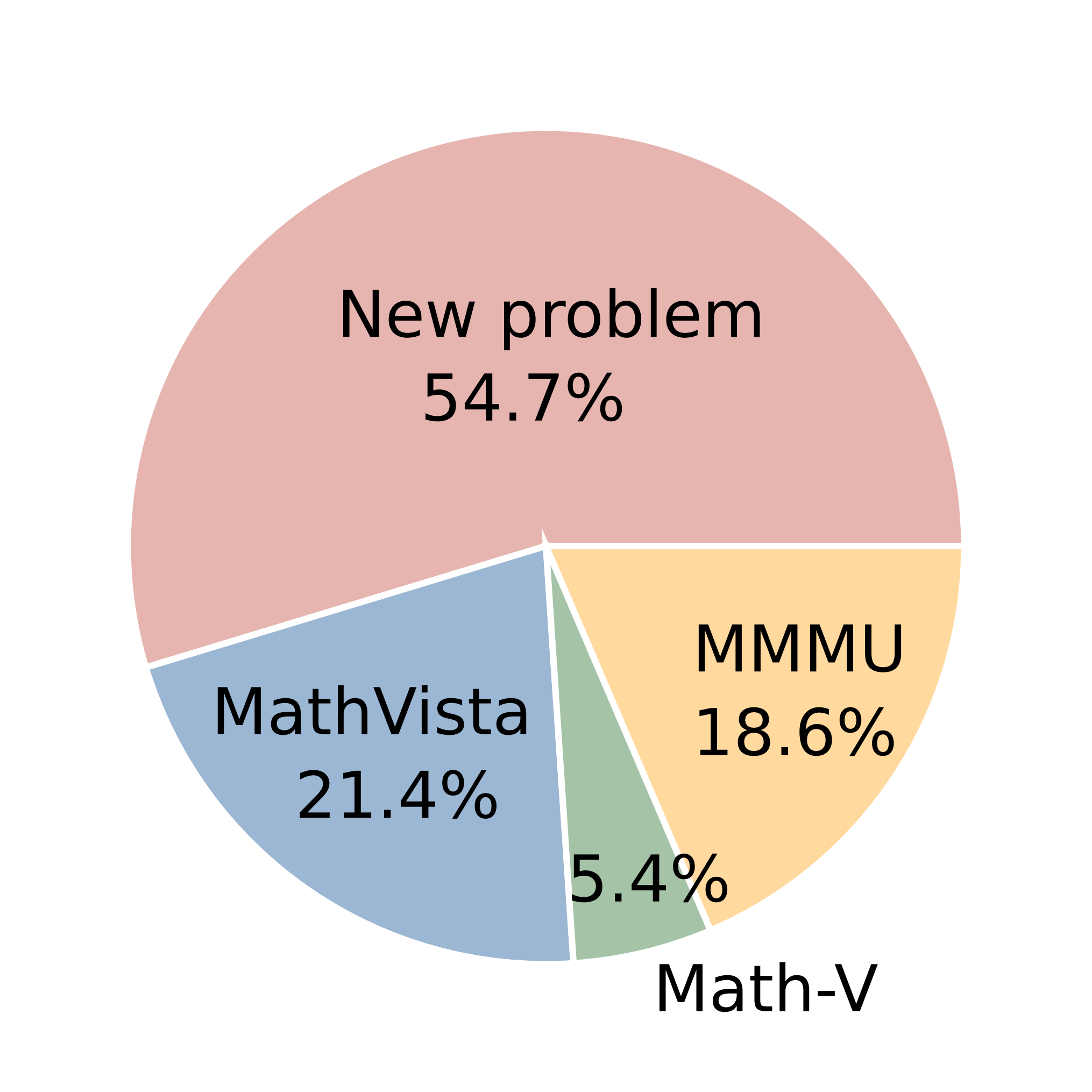
Source composition of
DynaMath.
In DynaMath, we integrate various types of variants to enrich the diversity of question generation:
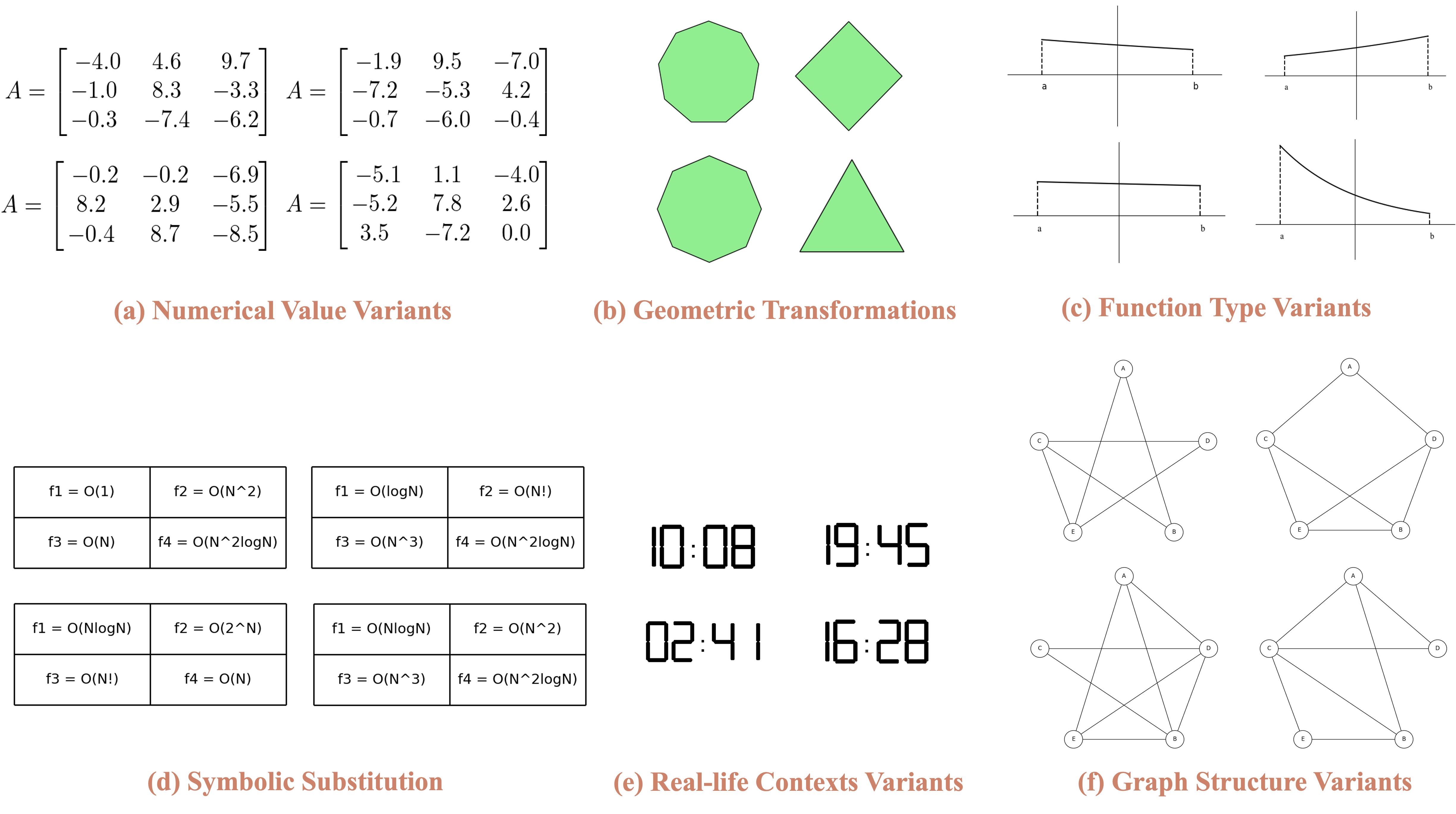
Several variantion types considered in our DynaMath benchmark.
Our benchmark collection comprises two phases: seed question collection and program-based question generation. In the initial phase, we selectively curate a set of high-quality mathematics problems that necessitate reasoning based on visual information. The subsequent phase involves transforming each seed question into code-based prototypes, allowing for the generation of diverse concrete questions under randomly sampled conditions.
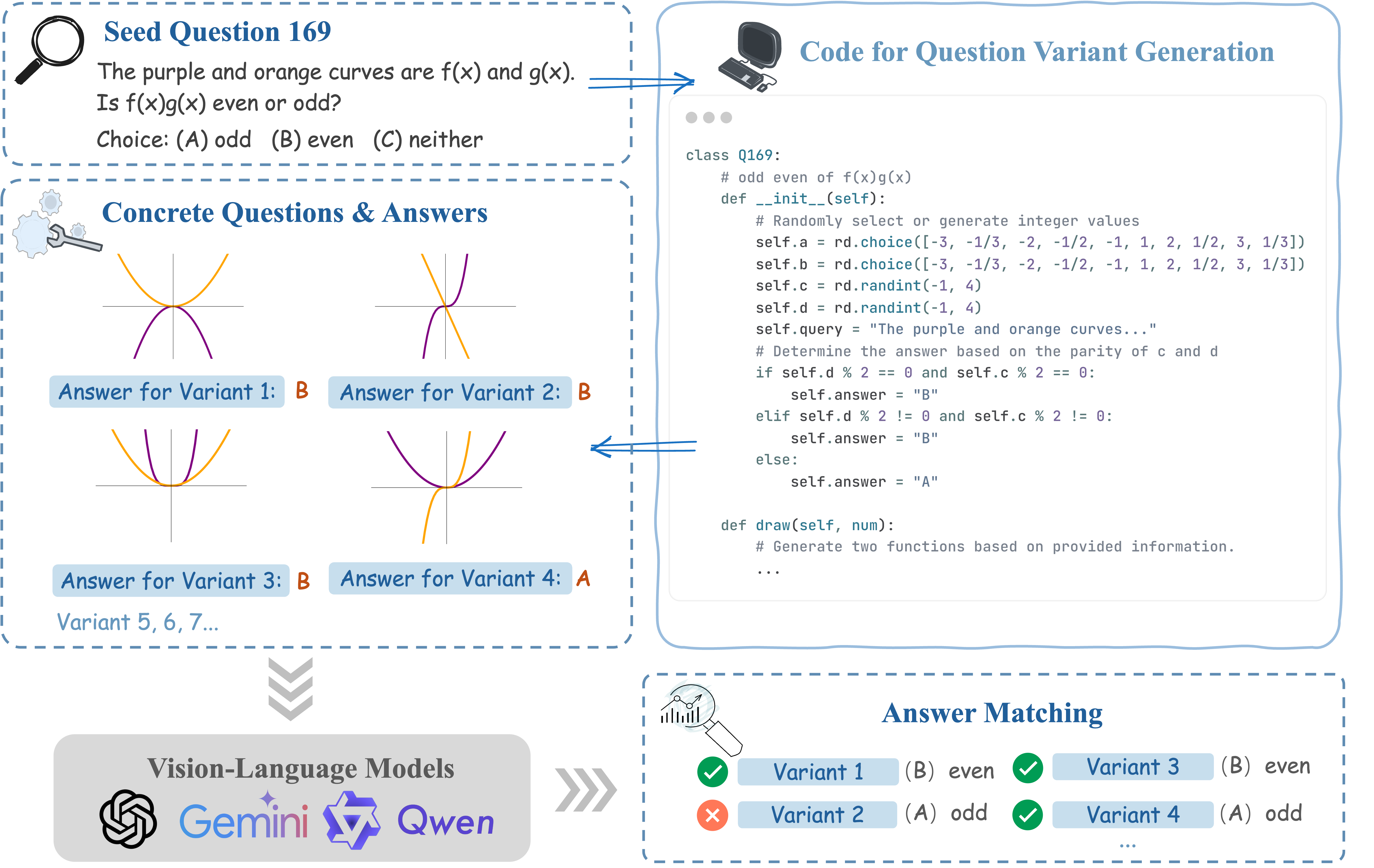
Generation Procedure in DynaMath.
Seed Question 169:
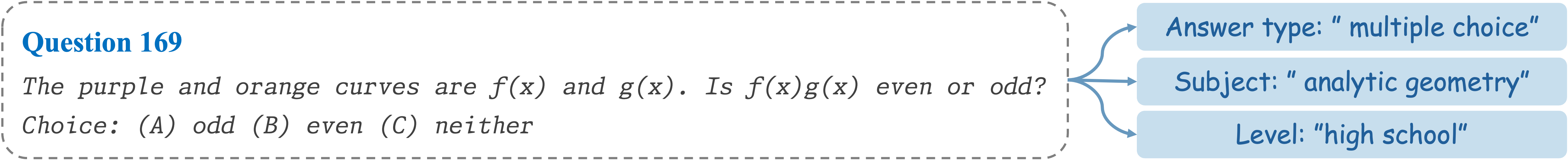
Response from GPT-4o:
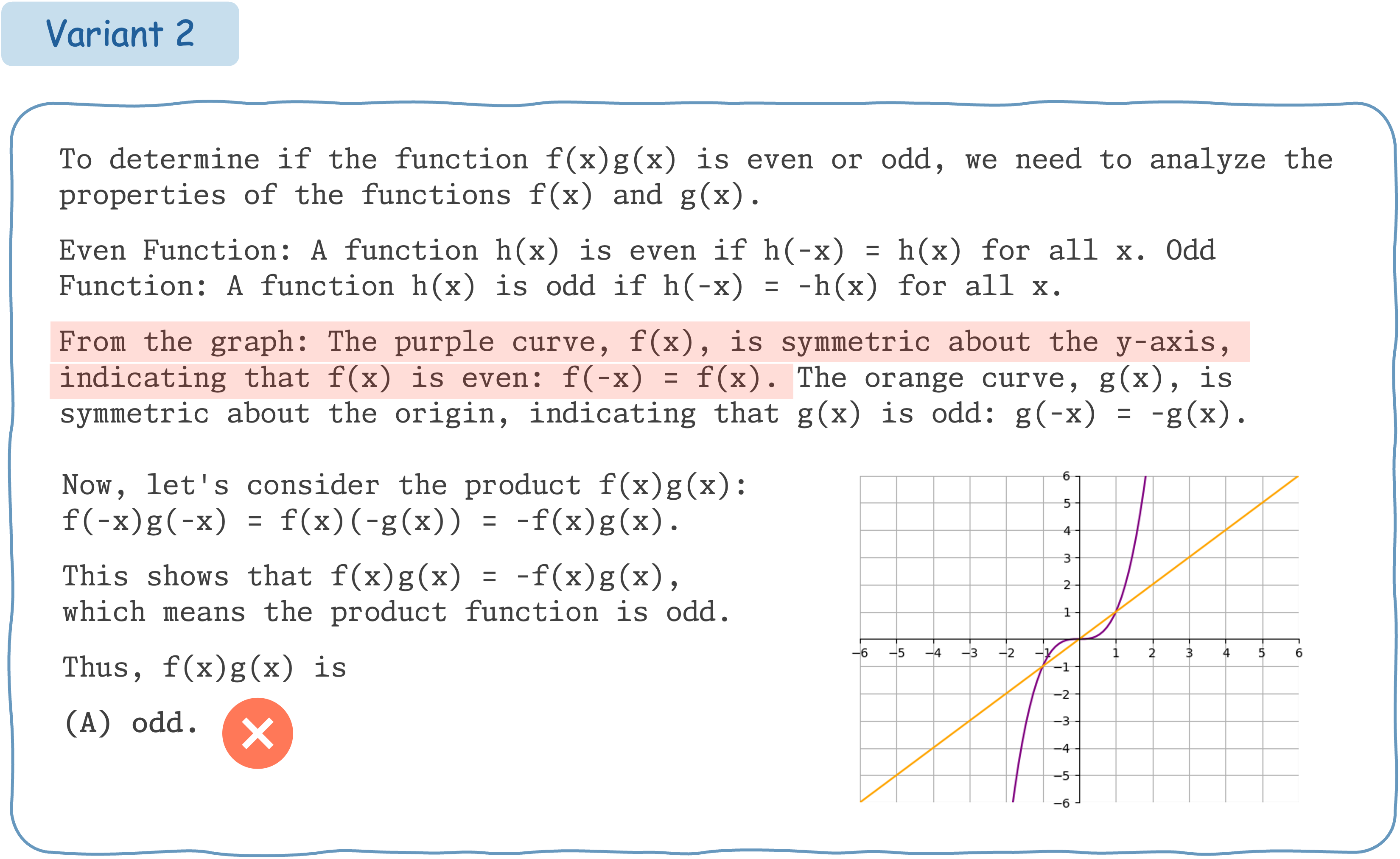
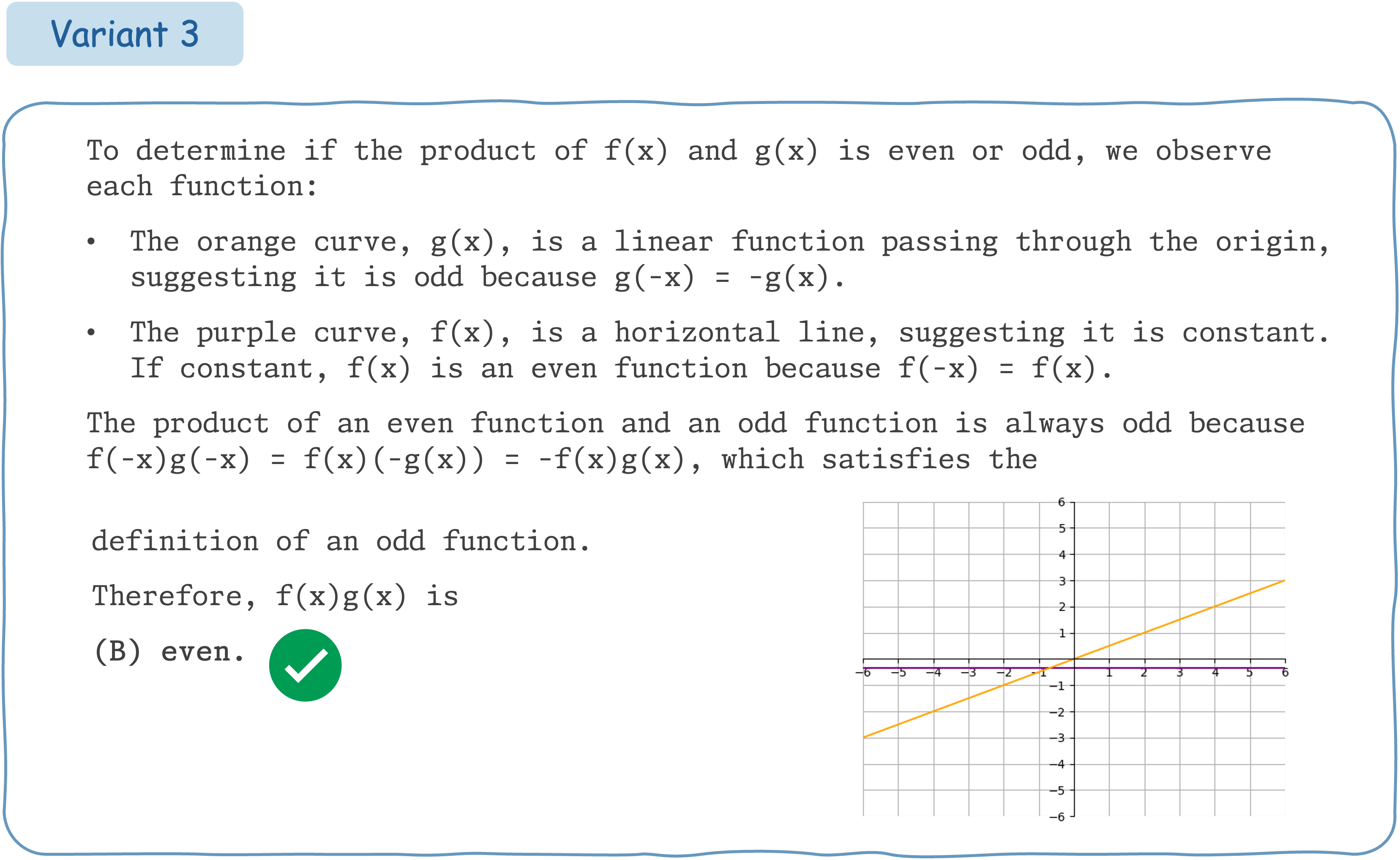
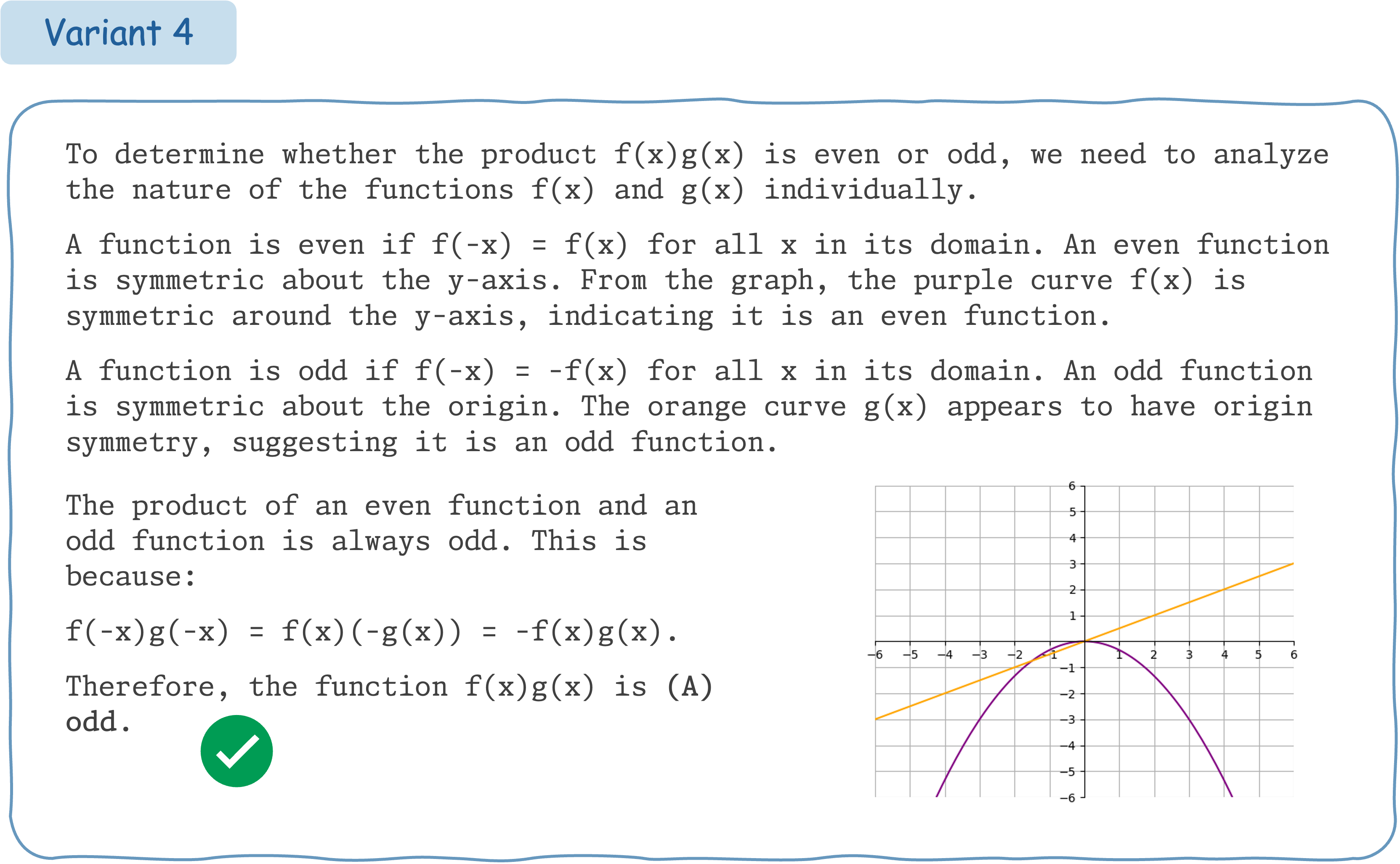
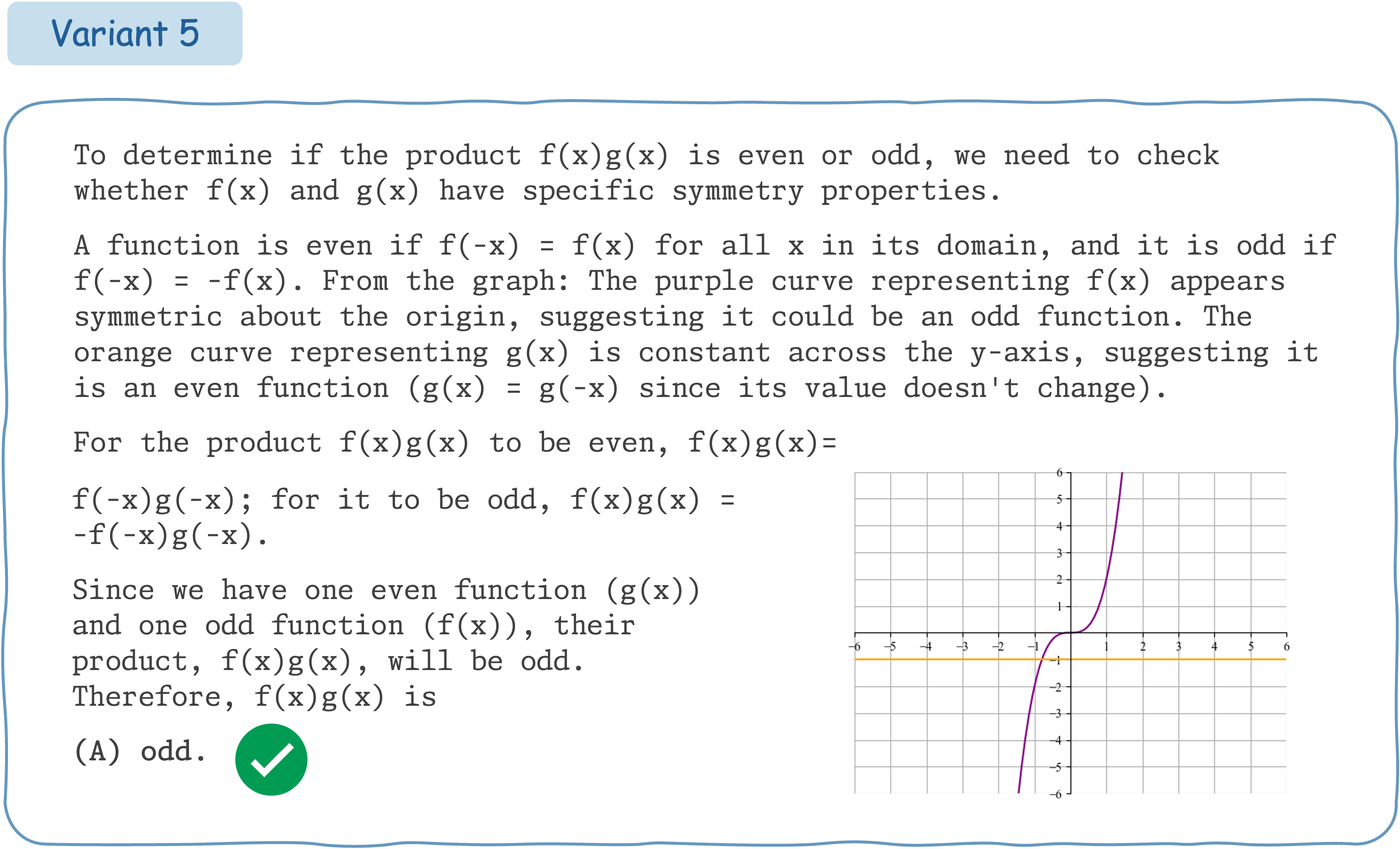
Seed Question 75:

Response from Gemini:
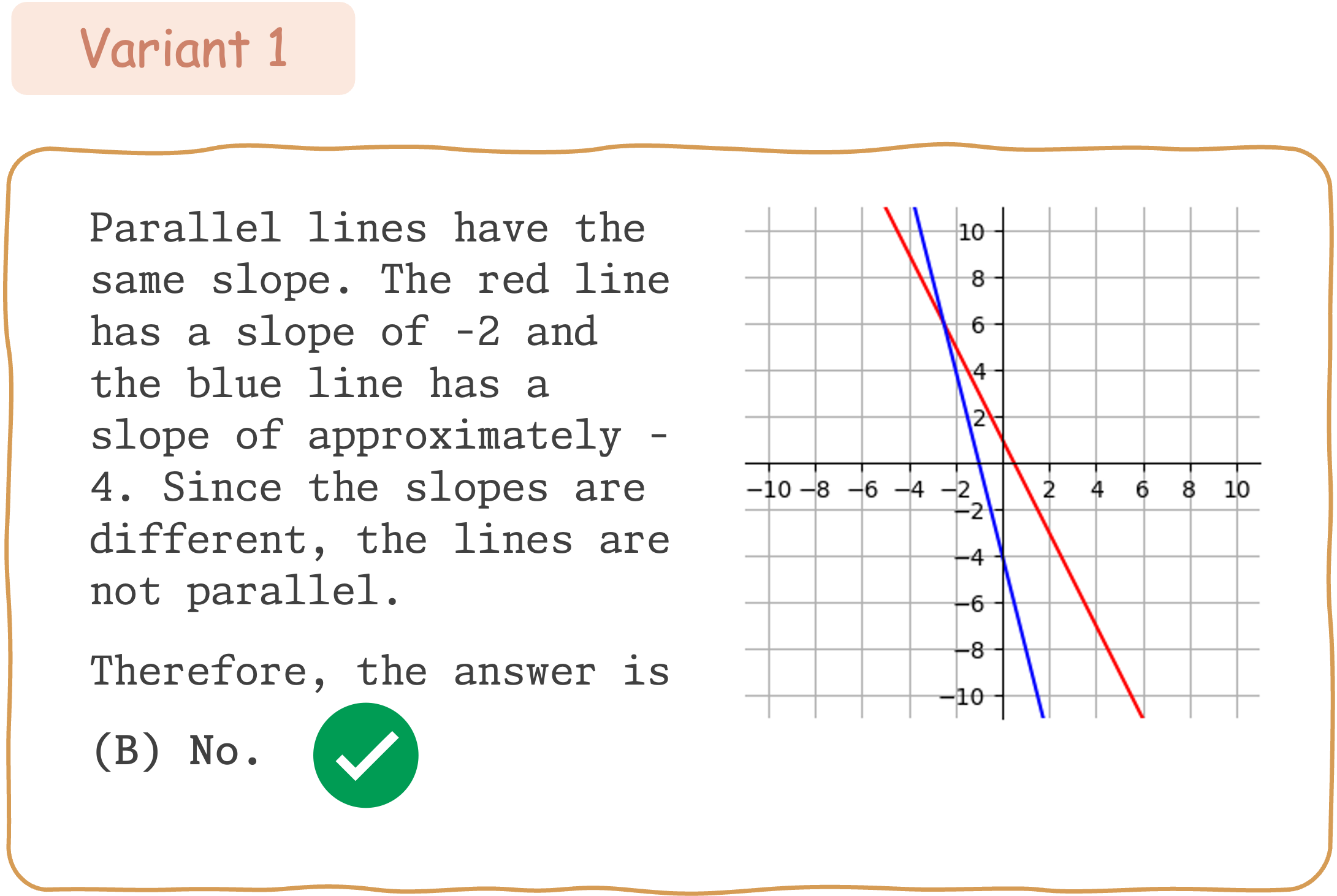
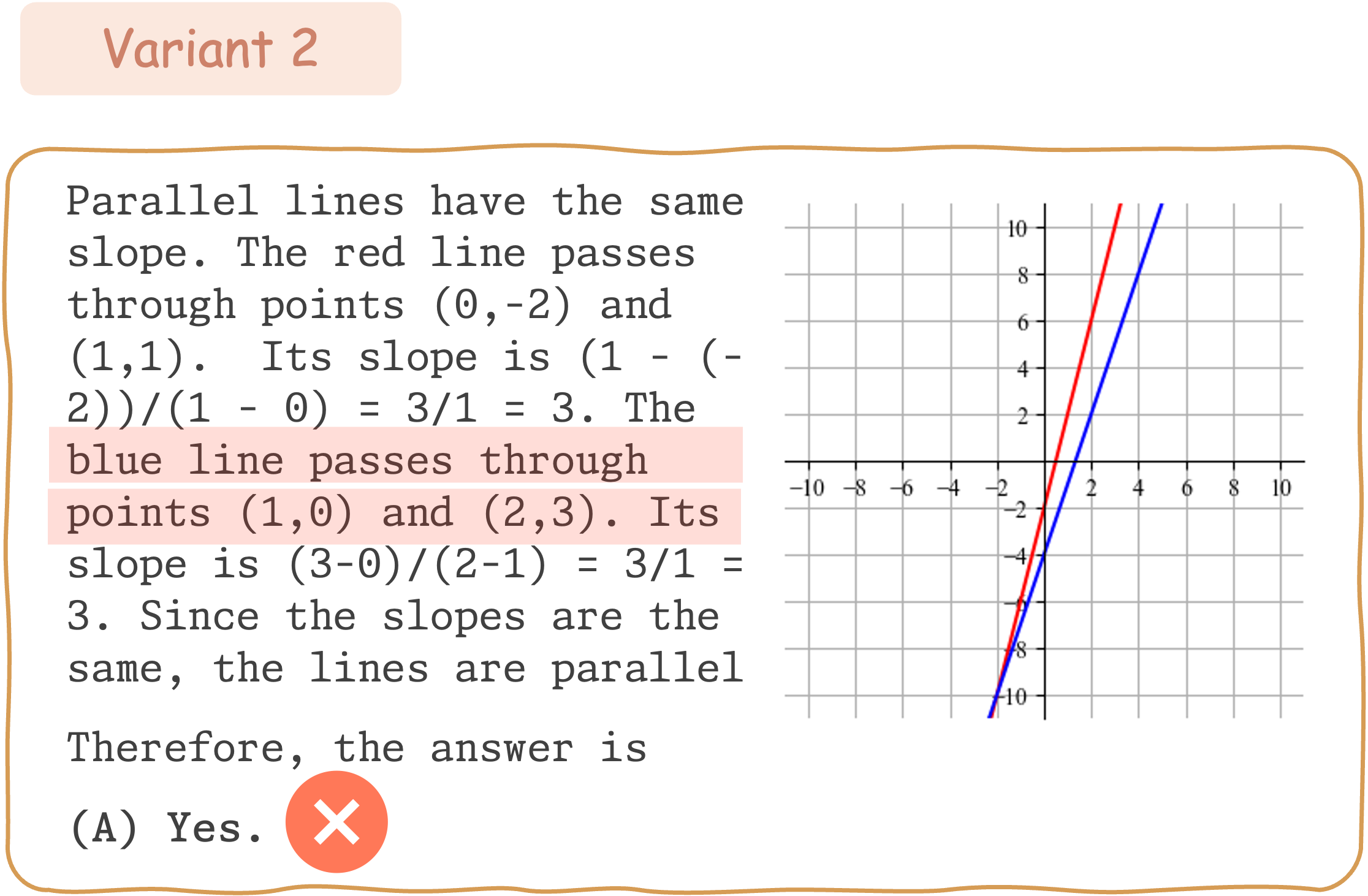
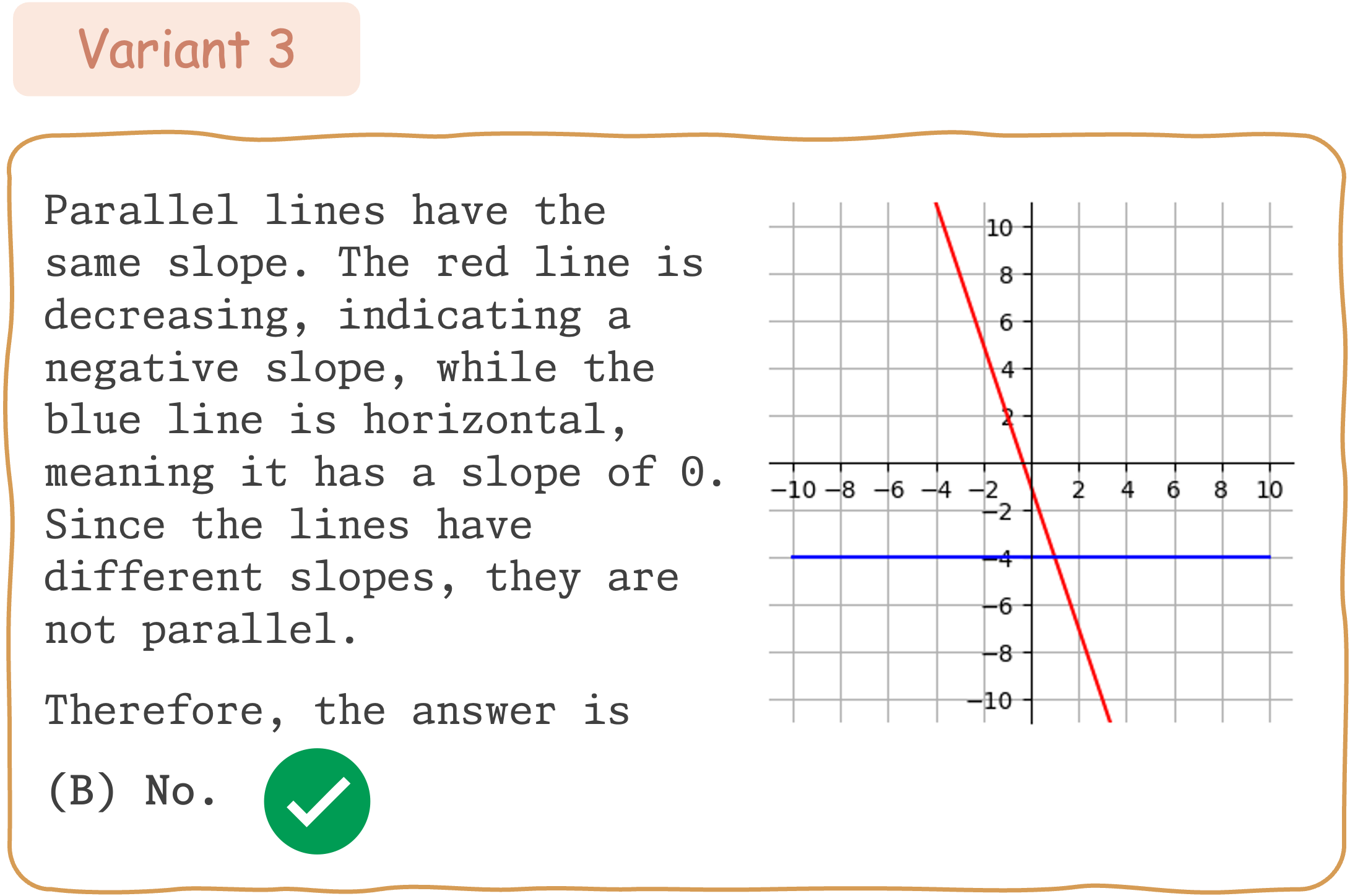
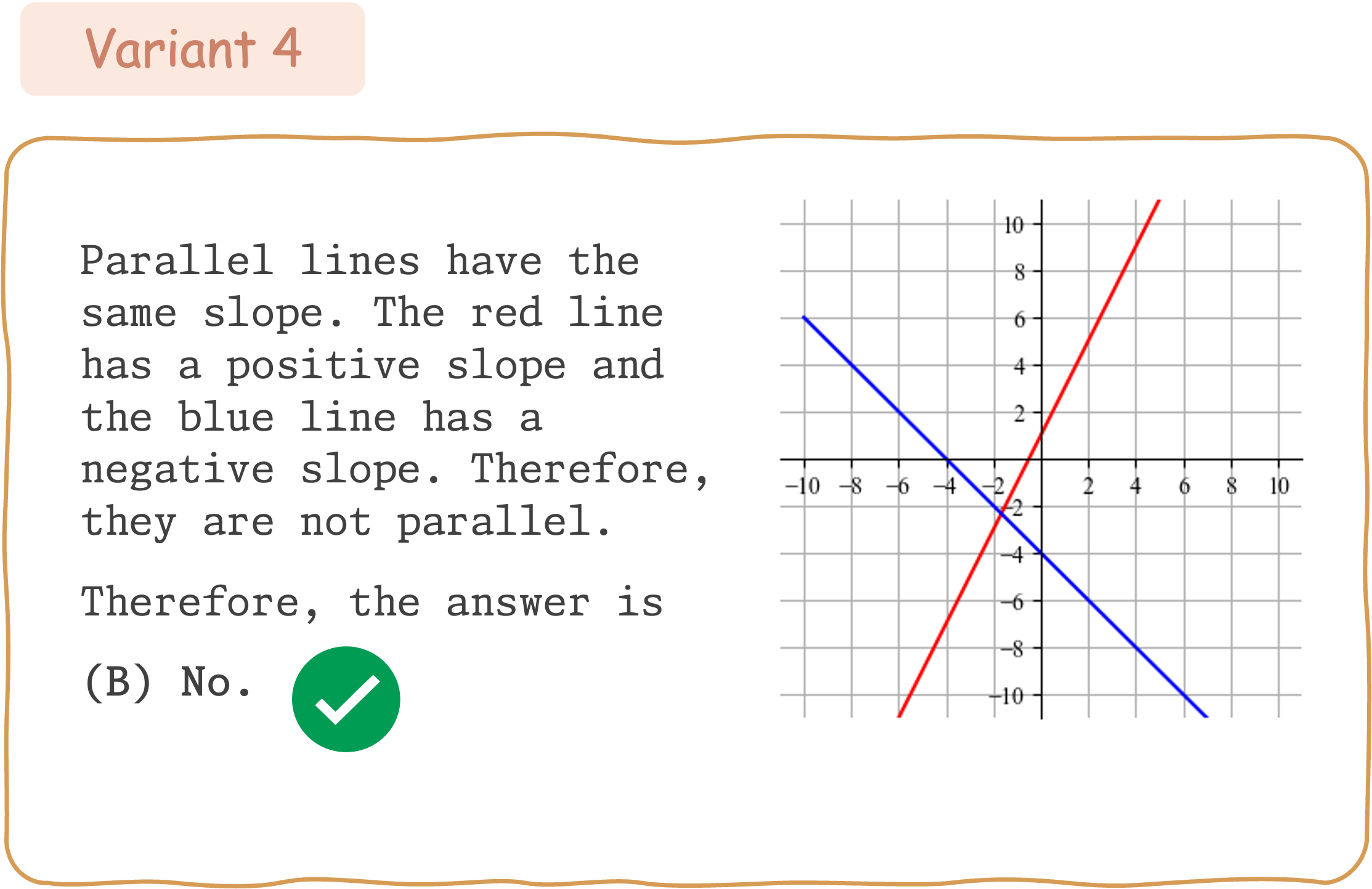
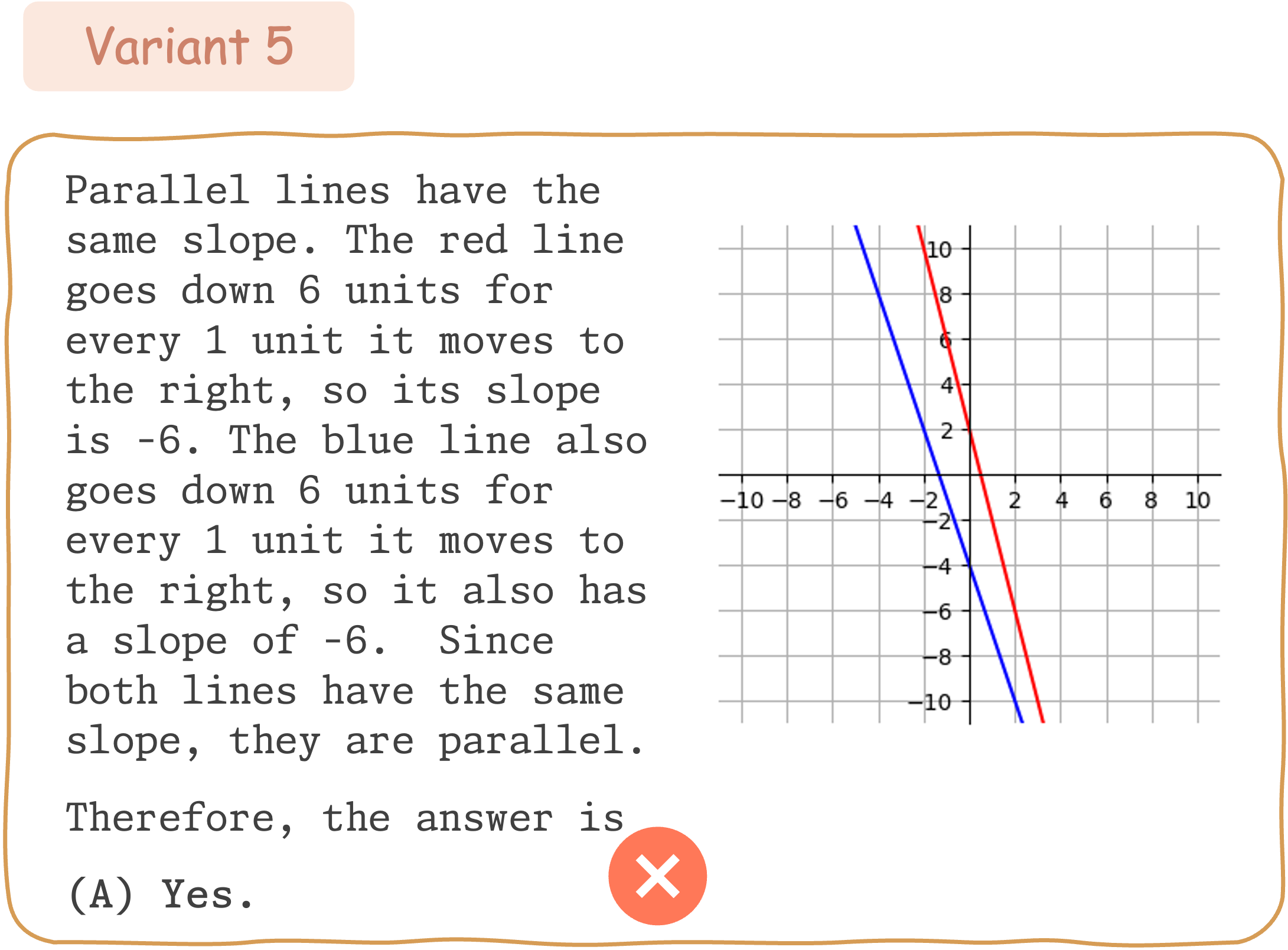
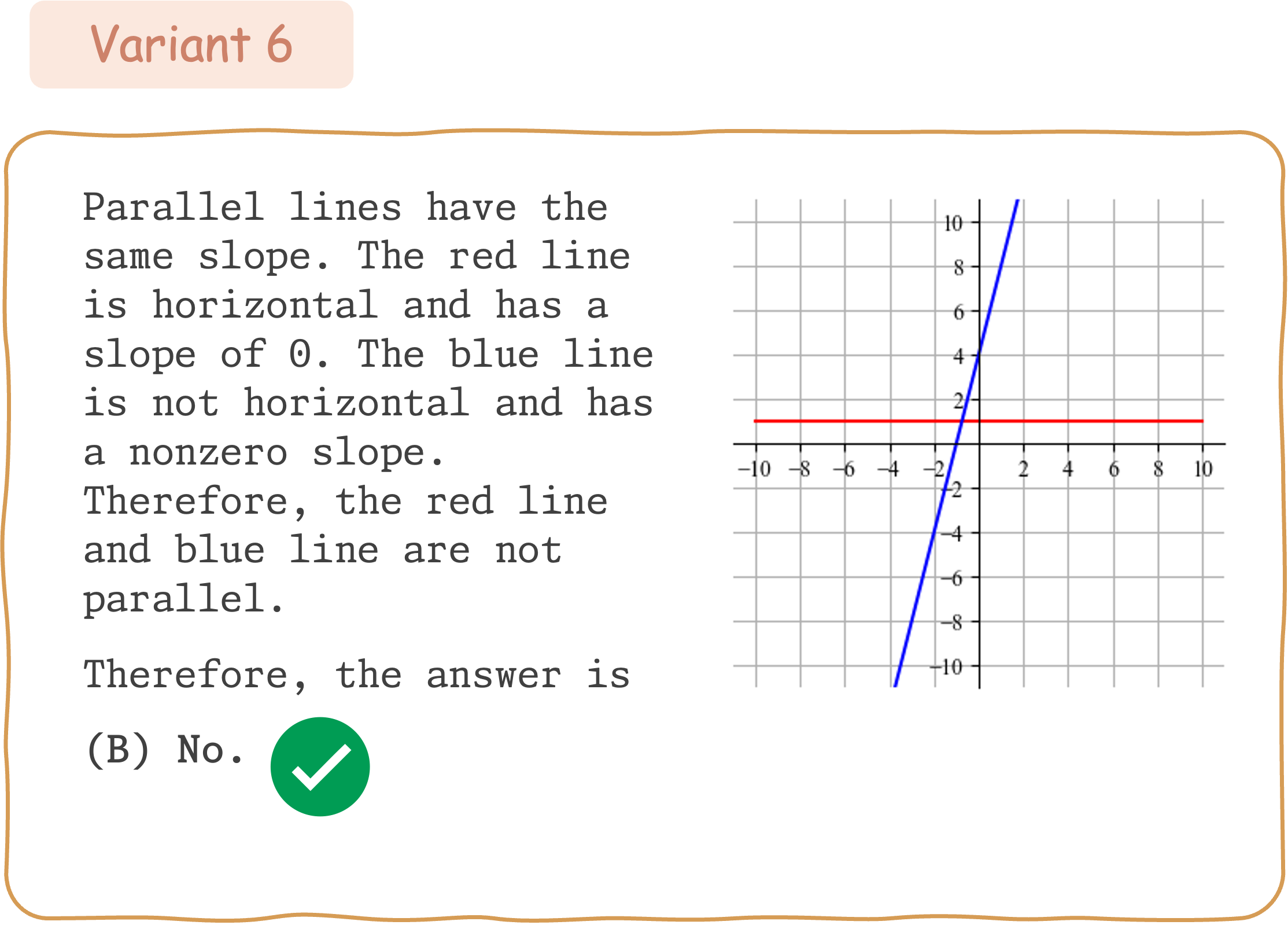
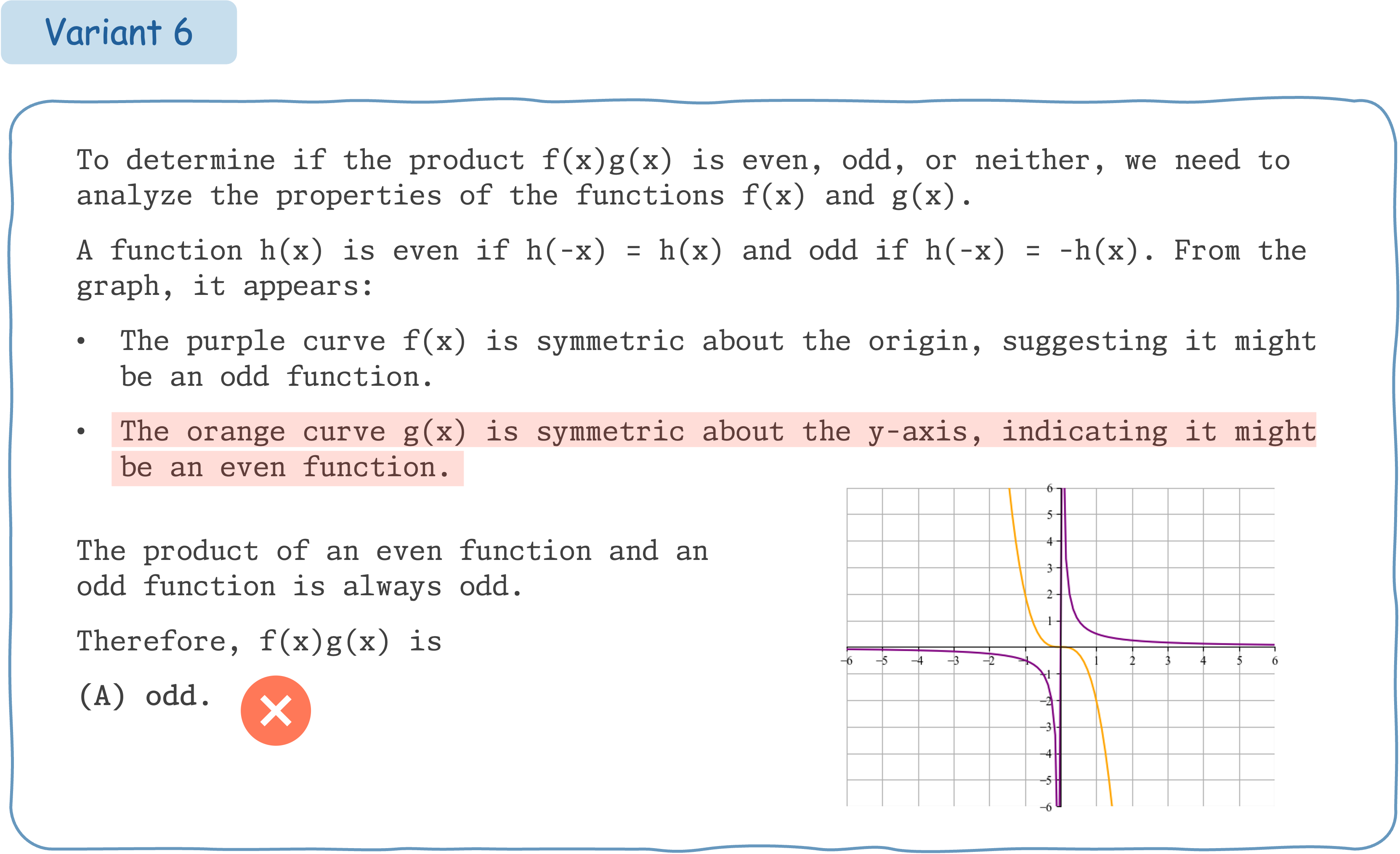
Seed Question 346:

Response from Qwen2-VL-72B:
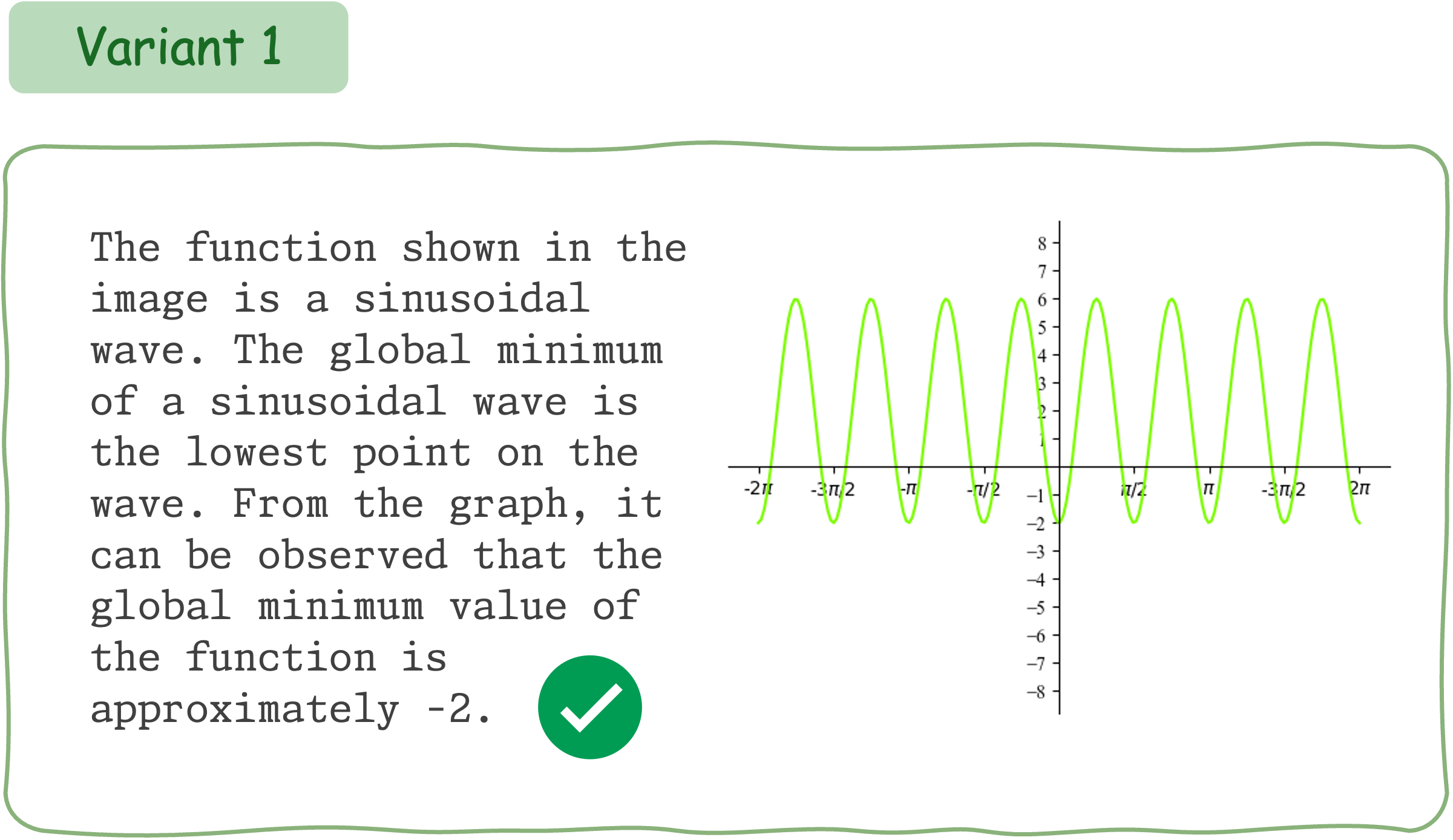
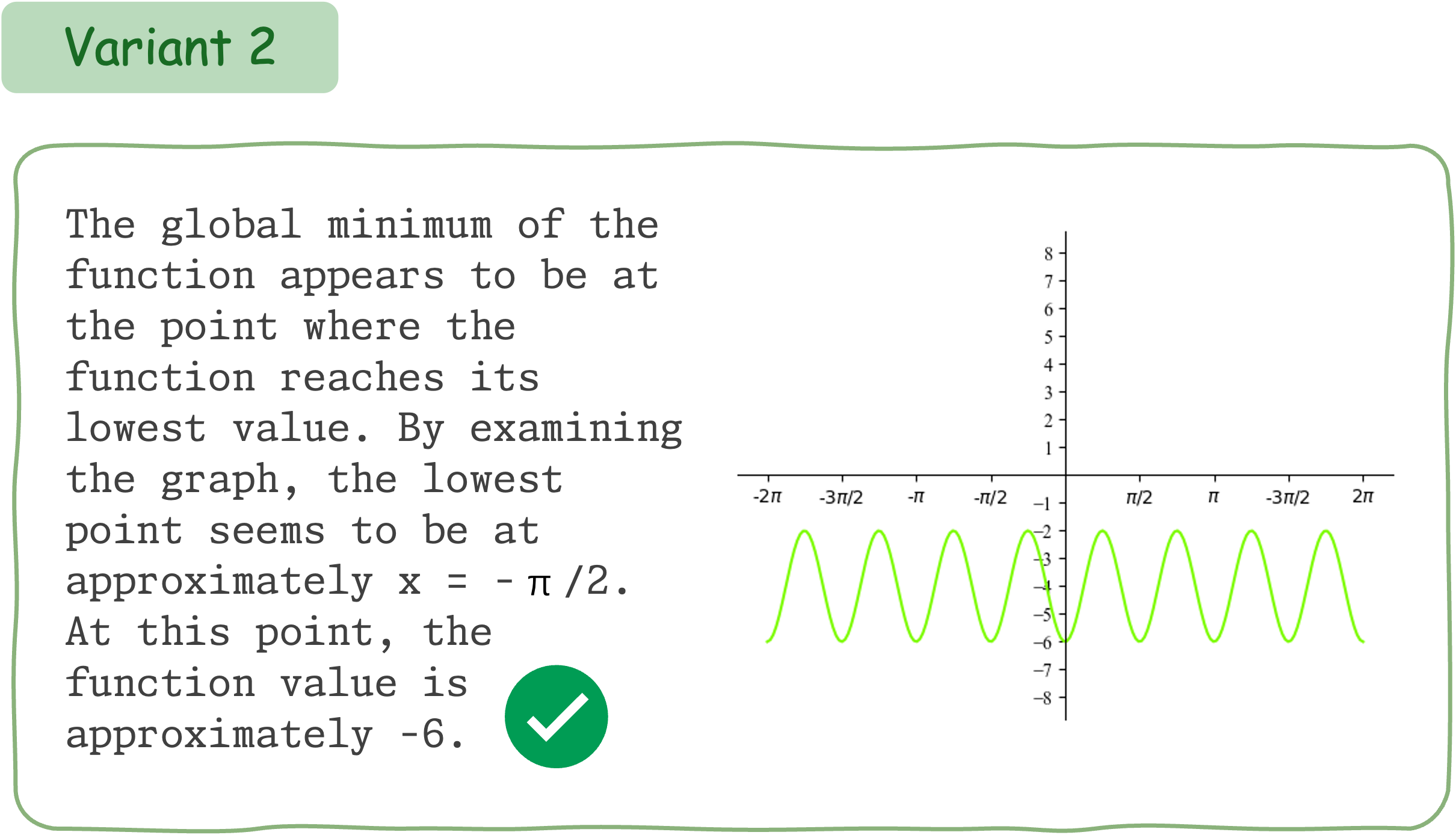
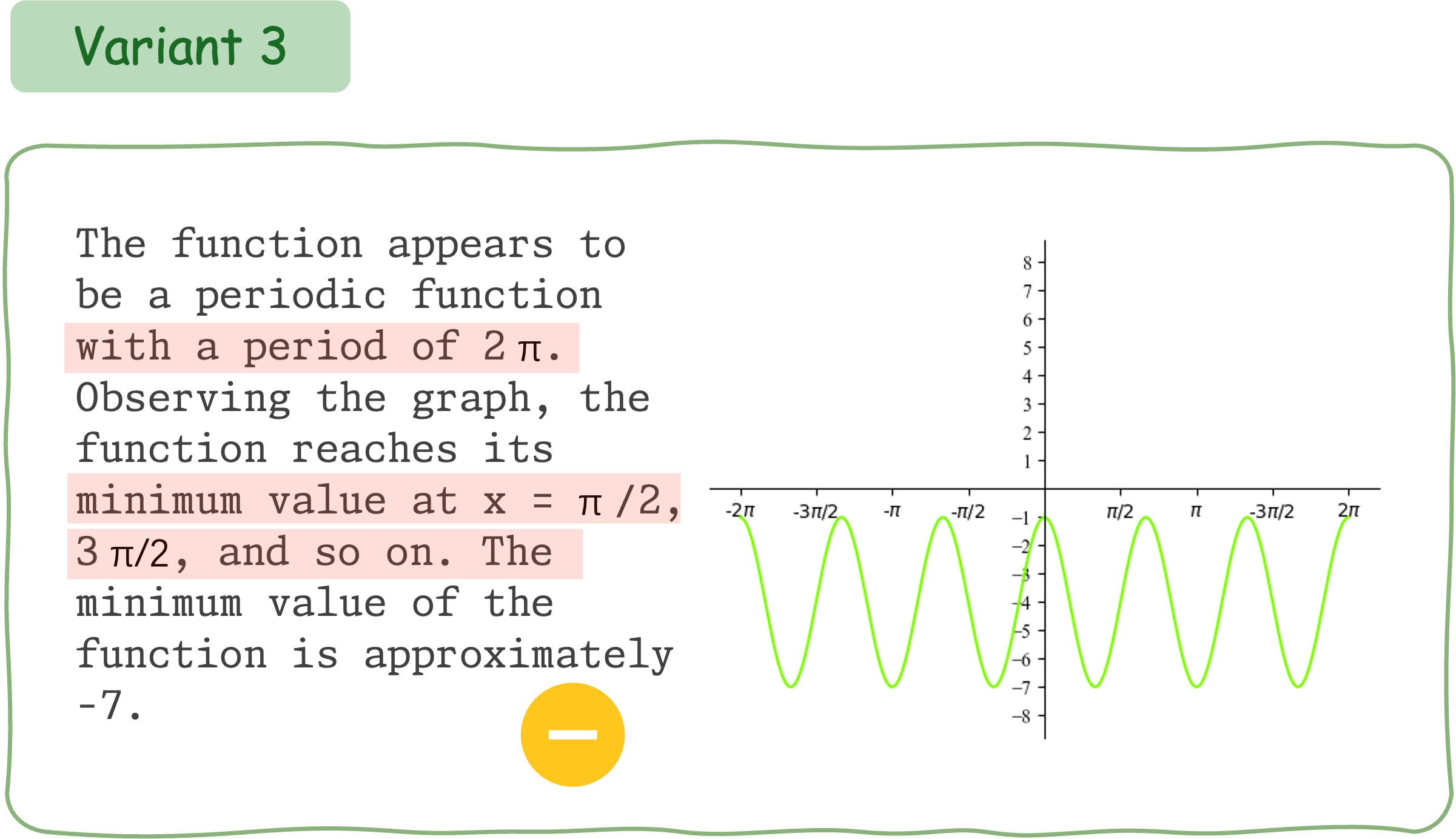
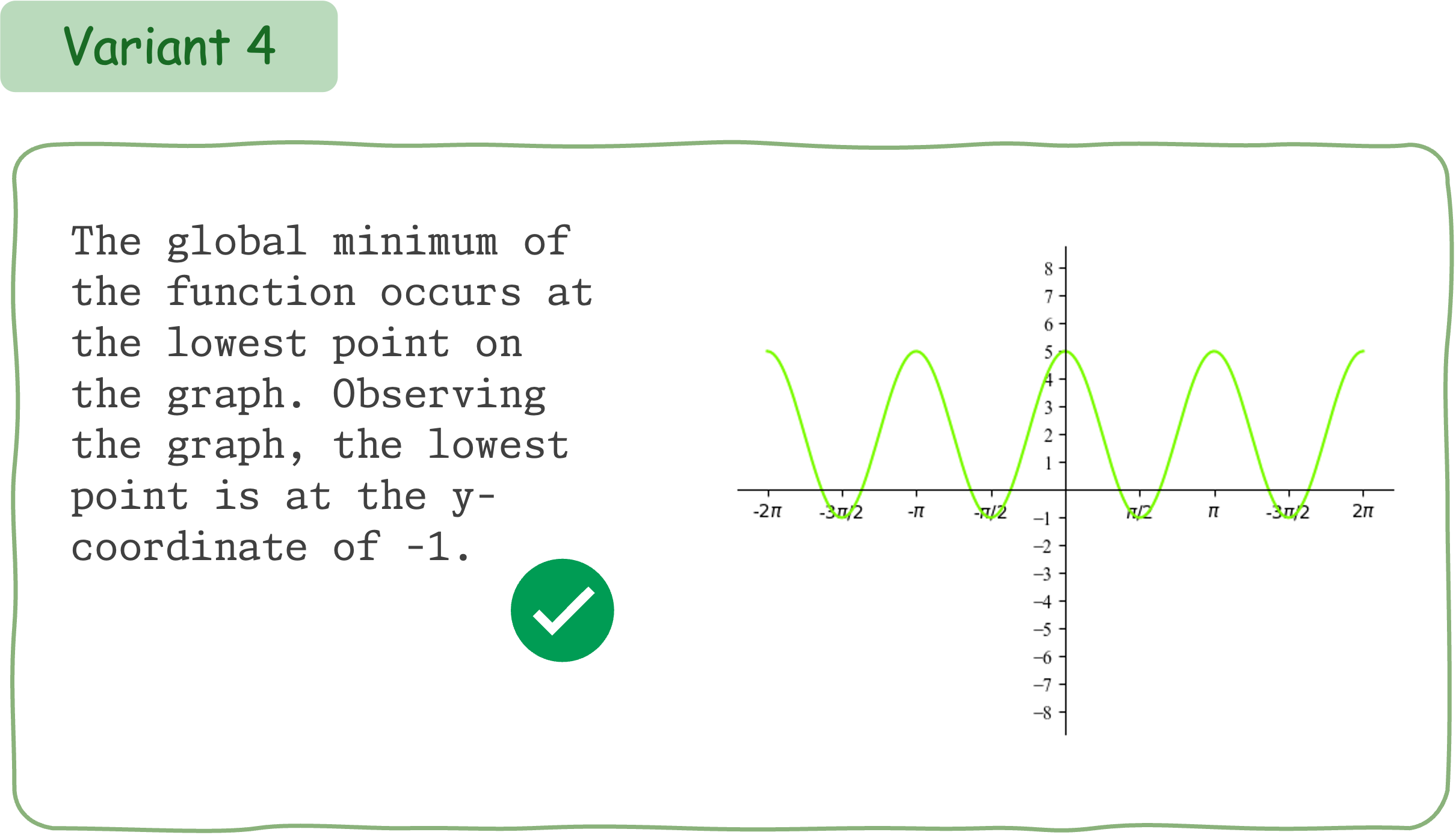
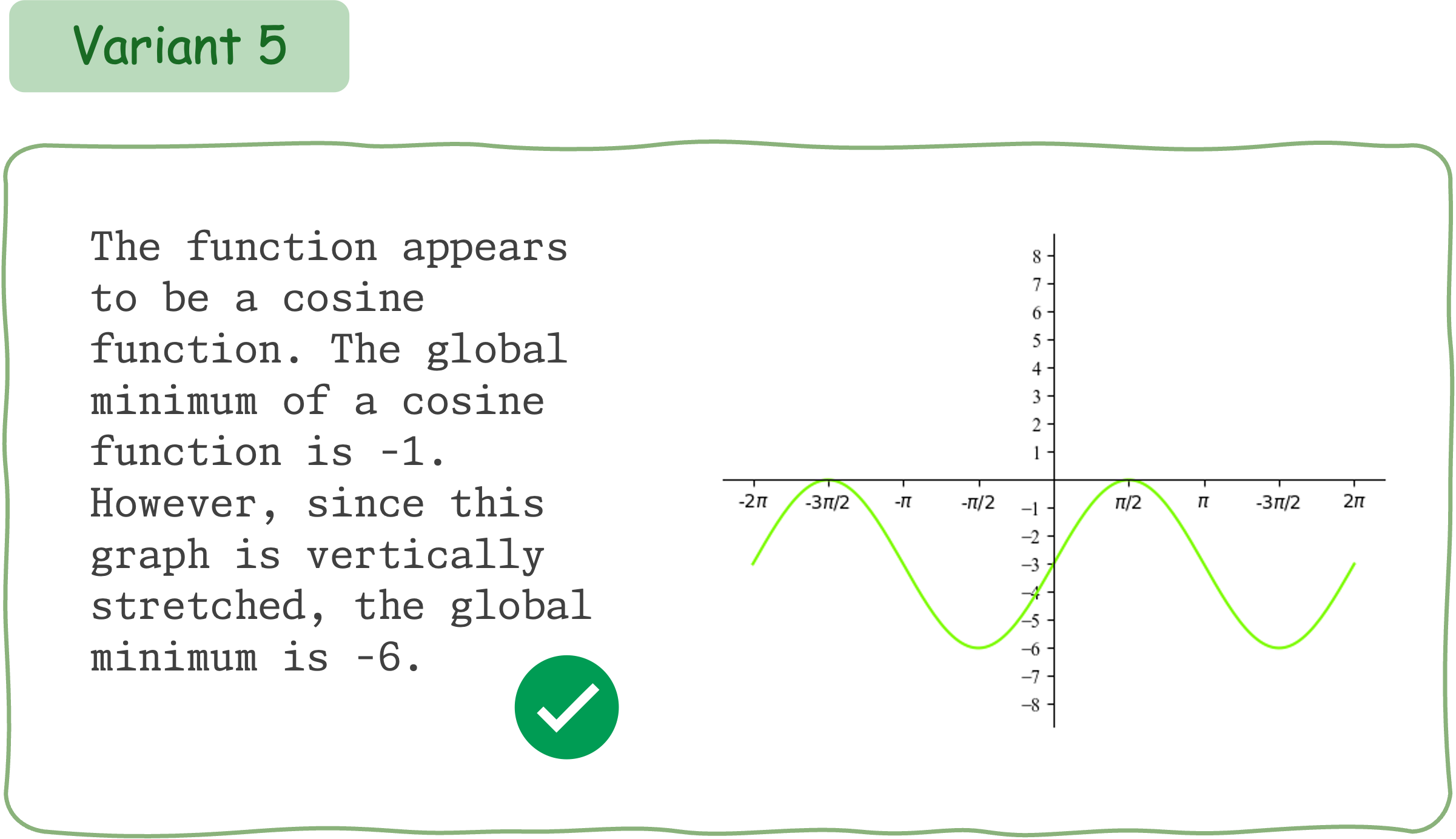
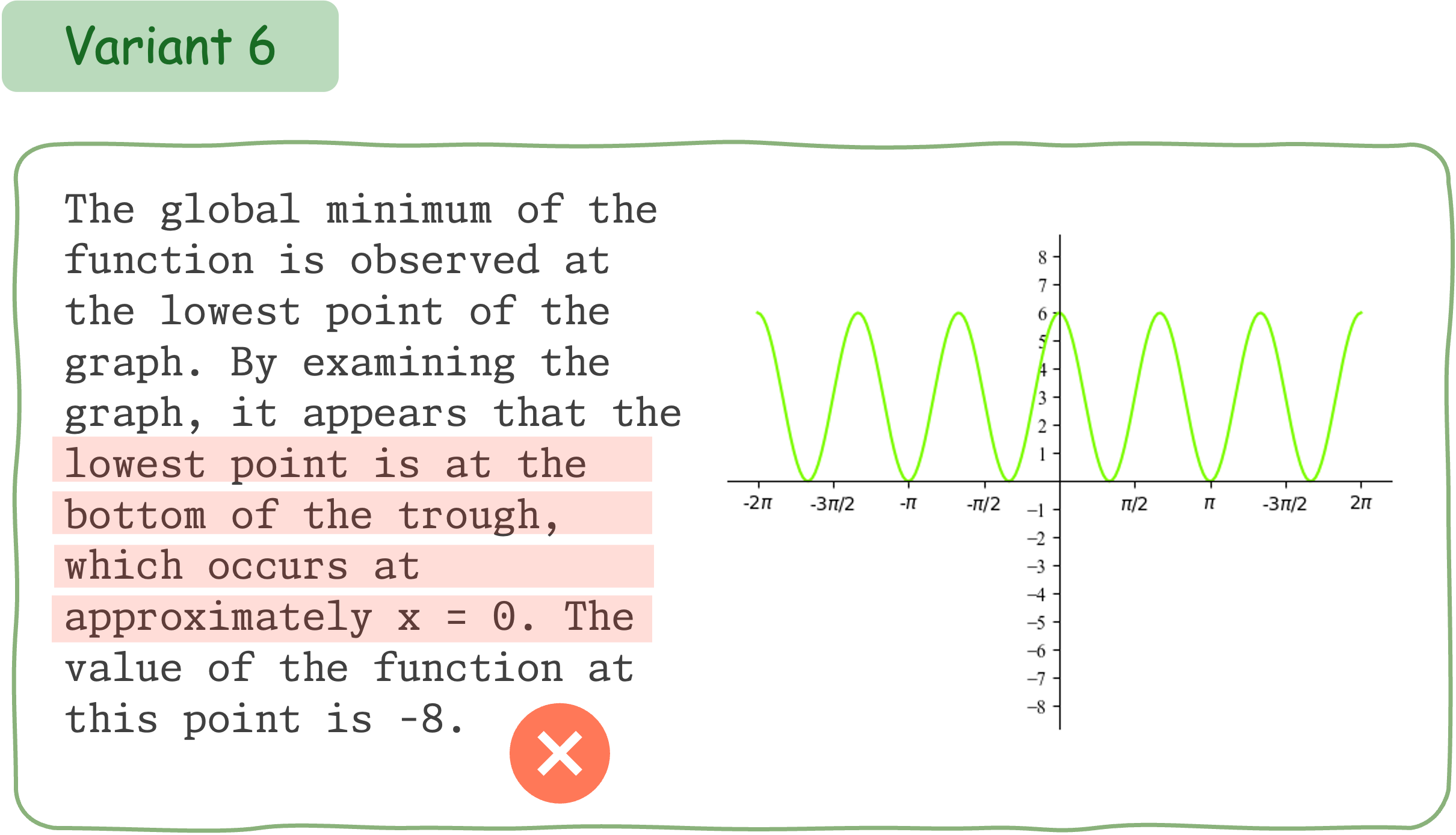
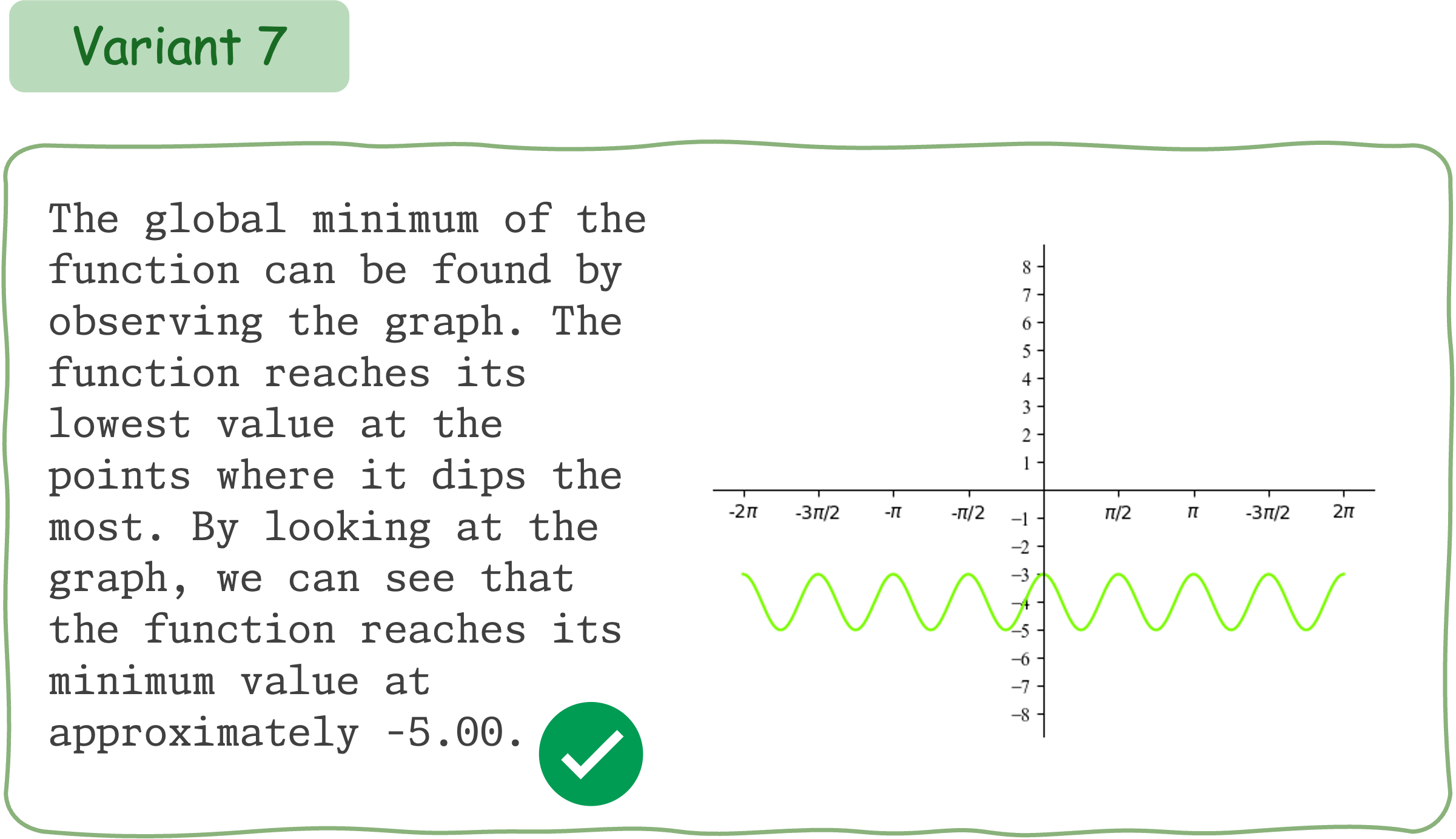
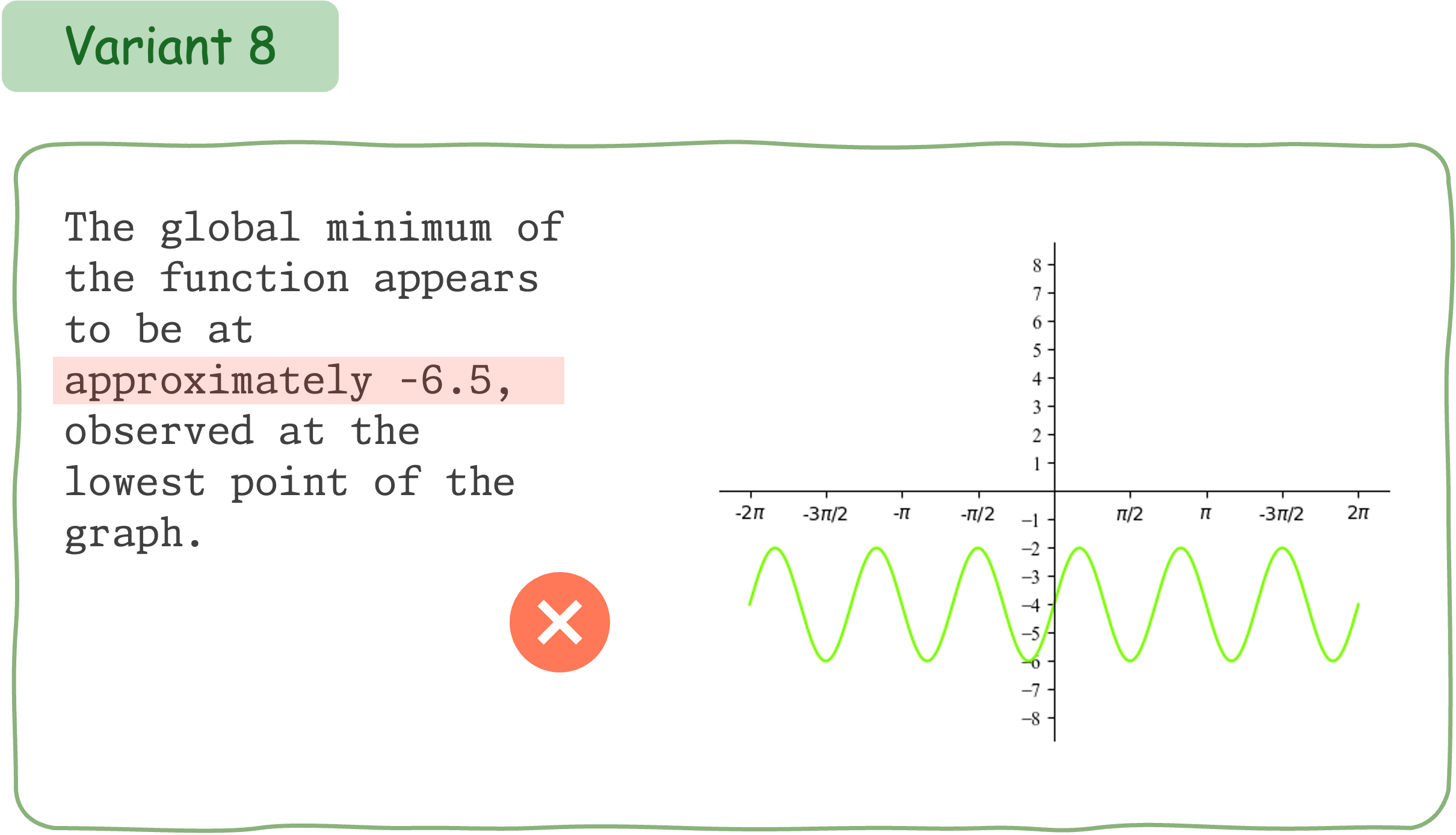
To evaluate the mathematical reasoning robustness of existing VLMs on DynaMath, we generate 10 variants, resulting in a total of 5,010 questions to assess their performance.
The table below shows the Average-case accuracy of 14 models (three Closed-sourced Large Multimodal Models (LMMs) and 11 Vision Language Models (VLMs)) on DynaMath with 5,010 generated questions. Question topics (PG, SG, EL, etc) and difficulty levels (EL, HI, UN) are defined in previous table.
The table below shows the Worst-case accuracy of 14 models (three Closed-sourced Large Multimodal Models (LMMs) and 11 Vision Language Models (VLMs)) on DynaMath with 5,010 generated questions. Question topics (PG, SG, EL, etc) and difficulty levels (EL, HI, UN) are defined in previous table.
Comparing Reasoning Robustness across different models. Here we define Reasoning Robustness (RR) as the ratio between the average-case performance and the worst-case performance.
Comparing Reasoning Robustness across different topics. Here we define Reasoning Robustness (RR) as the ratio between the average-case performance and the worst-case performance.

The Repetition Consistency for different models over 5 repetitions. The repetition consistency represents the model's confidence in the answer.

Error Analysis of Claude-3.5 Sonnet.
@misc{zou2024dynamic,
title={DynaMath: A Dynamic Visual Benchmark for Evaluating Mathematical Reasoning Robustness of Vision Language Models},
author={Chengke Zou and Xingang Guo and Rui Yang and Junyu Zhang and Bin Hu and Huan Zhang},
year={2024},
archivePrefix={arXiv},
primaryClass={cs.CL},
}
